There’s a post title you can’t say 3 times fast. As you may know, the Data Export Service for Dataverse, long used to get a SQL copy of data from Dataverse / CDS / Dynamics, is being retired later this year.
If you follow Microsoft’s Playbook for moving over to Synapse Link for Dataverse, you might just manage to get your data tables there without too much trouble. But one thing you won’t get easily is the old metadata tables, for resolving lookup IDs in the data to their text values.
This post is going to outline one approach for recreating those tables, if that’s your jam.
If you’re trying to create a SQL database pretty close to the output of the old Data Export Service, chances are that you used the Data Factory template provided by Microsoft for getting your data from Data Lake to SQL.
Y’know. This one.

From a bit of reading, you can find that the metadata is there in the underlying Azure Data Lake, as JSON files in the catchily named “Microsoft.Athena.TrickleFeedService” folder, as files named {entityName}-EntityMetadata.json.
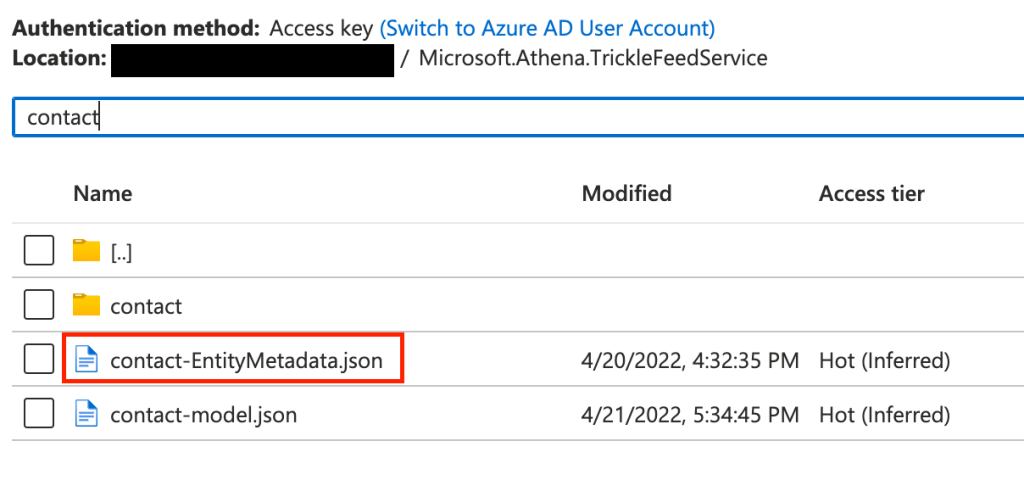
So in our Data Factory, we can add a new line in the existing Data Flow to push the metadata to a SQL table. The source type can still be Inline (like the existing source), but the Inline dataset type should be JSON.
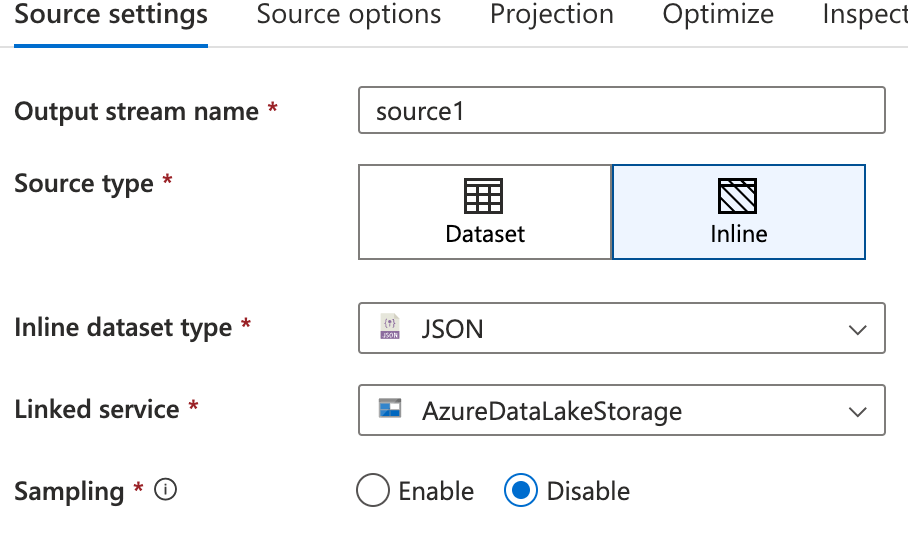
Under Source options, use the Browse option to choose the relevant metadata JSON file from your storage account, at the location shown above. This is much easier than manually providing the correct values.
You might want to use the Projection tab to Import schema at this point (requires Data flow debug to be on), seems to help mapping in the next step.
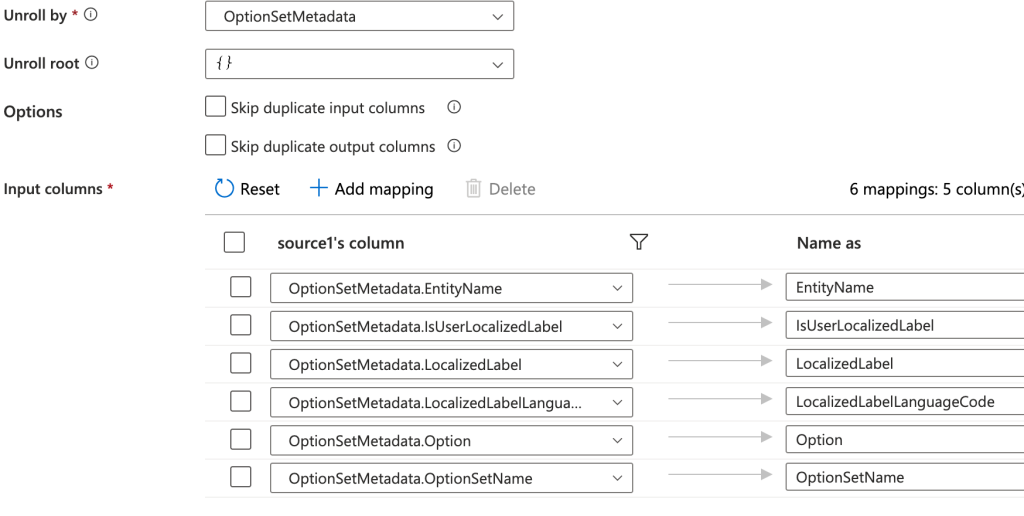
After the source shape, you can use a Flatten shape to grab the particular metadata array you’re trying to import. (You could also do several flatten shapes if you want to bring in more than one, but let’s start with one). In the Flatten settings, for Unroll by, choose the array you’re trying to import to a table. For me, it was the OptionSetMetadata I was after. You can then update Input columns to map the structure to your table. It might end up looking a bit like this.
Finally, you can use a Sink shape to send the data to a Dataset representing your metadata table. There’s not a huge amount to say about this, other than you can leave Automapping on if you already mapped the names as shown above.
Once you’re done, your data flow should have a second row for your metadata, and it might look like this, except you will give your shapes proper names because you aren’t lazily testing something like me. You can do better than “sink1”.

That’s one way to get the metadata into your SQL sink. I’m not saying it’s the best way, and I may update this later after more time experimenting, but today’s experiments suggest it does work.